File Access: Difference between revisions
pc>Yuron No edit summary |
m 1 revision imported |
||
| (2 intermediate revisions by 2 users not shown) | |||
| Line 2: | Line 2: | ||
-->{{Path|Filing|7}}<!-- | -->{{Path|Filing|7}}<!-- | ||
-->{{#invoke:Dependencies|add|Files,4}} | -->{{#invoke:Dependencies|add|Files,4}} | ||
Users usually identify [[Files | files]] with <em>filenames</em> … or, more | Users usually identify [[Files | files]] with <em>filenames</em> … or, more formally, a <em>path</em> to a file. The name is a <strong>string</strong> which is an inconvenient item for the O.S. to handle. It is therefore usual to associate an abstract <strong>handle</strong> leading to a [[File Descriptor|file descriptor]] of a file which is in use. | ||
formally, a <em>path</em> to a file. The name is a <strong>string</strong> which is an | |||
inconvenient item for the O.S. to handle. It is therefore usual to | |||
associate an abstract <strong>handle</strong> leading to a [[ | |||
descriptor]] of a file which is in use. | |||
Exactly <em>what</em> the handle is does not usually matter to a user: it | Exactly <em>what</em> the handle is does not usually matter to a user: it could be a simple index, a virtual address etc. It is just ‘something’ with which the user can identify a particular file. | ||
could be a simple index, a virtual address etc. It is just | |||
‘something’ with which the user can identify a particular | |||
file. | |||
This gives access to the file descriptor via various | This gives access to the file descriptor via various ‘method’ calls. | ||
‘method’ calls. | |||
[[Image:file_access.png|link=|alt=File Access Abstraction]] | [[Image:file_access.png|link=|alt=File Access Abstraction]] | ||
| Line 20: | Line 12: | ||
[[Exercises:Files | There are accompanying exercises …]] | [[Exercises:Files | There are accompanying exercises …]] | ||
The first thing to do is always to <em>open</em> a file – here opened for | The first thing to do is always to <em>open</em> a file – here opened for reading. This will then fetch a block of the file into a buffer which prevents a disk access on every <em>Read</em> call. ([[Caching]] again!) Reads are then made from the buffer, which is refilled when necessary. | ||
reading. This will then fetch a block of the file into a buffer which | |||
prevents a disk access on every <em>Read</em> call. ([[Caching]] | |||
again!) Reads are then made from the buffer, which is refilled when | |||
necessary. | |||
Read operations can continue until the End Of File, a point which | Read operations can continue until the End Of File, a point which prevents further reading. The file can be <em>closed</em> at any time. | ||
prevents further reading. The file can be <em>closed</em> at any time. | |||
<blockquote> | <blockquote> | ||
Other things may be mapped to ‘look like’ files and the | Other things may be mapped to ‘look like’ files and the same, <em>device independent</em> interface. These include: | ||
same, <em>device independent</em> interface. These include: | * [[Streams]] | ||
* [[ | * [[Pipes]] | ||
* [[ | * [[Device Drivers|Devices]] | ||
* [[ | |||
among [[Everything is a File|other things]]. | among [[Everything is a File|other things]]. | ||
</blockquote> | </blockquote> | ||
True files – although not purely serial streams – will also allow | True files – although not purely serial streams – will also allow <em>seek</em> operations where the position read from or written to is moved. A simple example would be a multi-pass compiler which could open a source file and read it serially, then move back to the start and read it again without closing it in the meantime. | ||
<em>seek</em> operations where the position read from or written to is moved. | |||
A simple example would be a multi-pass compiler which could open a | |||
source file and read it serially, then move back to the start and read | |||
it again without closing it in the meantime. | |||
The description below covers the ‘classic’ access | The description below covers the ‘classic’ access operations. Some operating systems also allow [[Memory Mapped Files]]. | ||
operations. Some operating systems also allow [[Memory Mapped Files]]. | |||
=== Open === | === Open === | ||
To obtain a file handle it is necessary to “open” a file. | To obtain a file handle it is necessary to “open” a file. This [[System_Calls | system call]] will assign a handle to the required filename/path for the relevant process (the last time this <em>string</em> is needed), check and set up the appropriate permissions and reset the file’s (internal position) <em>pointer</em> to the start (or end, if “appending”). It can fail and thus signal various errors. | ||
This [[System_Calls | system call]] will assign a handle to the required | |||
filename/path for the relevant process (the last time this <em>string</em> is | |||
needed), check and set up the appropriate permissions and reset the | |||
file’s (internal position) <em>pointer</em> to the start (or end, if | |||
“appending”). It can fail and thus signal various errors. | |||
=== Close === | === Close === | ||
When a file is finished with it should be “closed”. This | When a file is finished with it should be “closed”. This may – for example – be needed before another process can write to | ||
may – for example – be needed before another process can write to | |||
that file. | that file. | ||
Closing the file will also flush any remaining <strong>buffered</strong> data to | Closing the file will also flush any remaining <strong>buffered</strong> data to the file itself. | ||
the file itself. | |||
The O.S. may close any remaining open files a process owns when the | The O.S. may close any remaining open files a process owns when the process terminates, but it is <em>good practice</em> to tidy up as a matter of course. | ||
process terminates, but it is <em>good practice</em> to tidy up as a matter | |||
of course. | |||
=== Reading and Writing === | === Reading and Writing === | ||
For efficiently reducing the number of [[ | For efficiently reducing the number of [[System Calls|system calls]] needed it is usual to read or write <strong>blocks</strong> of data, although library calls such as <code>fgetc()</code> may reduce this to ‘blocks’ of one byte at a time. | ||
needed it is usual to read or write <strong>blocks</strong> of data, although | |||
library calls such as <code>fgetc()</code> may reduce this to | |||
‘blocks’ of one byte at a time. | |||
Typical read or write operations move a contiguous number of bytes or | Typical read or write operations move a contiguous number of bytes or words from the current position in a file to a specified memory buffer, or vice versa. The position in the file is advanced by the same distance because file operations are, mostly assumed to be <strong>serial</strong>. | ||
words from the current position in a file to a specified memory | |||
buffer, or vice versa. The position in the file is advanced by the | |||
same distance because file operations are, mostly assumed to be | |||
<strong>serial</strong>. | |||
=== Seeking === | === Seeking === | ||
It is possible to apply some ‘random access’ to files in | It is possible to apply some ‘random access’ to files in the same way as the computer can to its memory, although the process | ||
the same way as the computer can to its memory, although the process | is somewhat more expensive! Rather than simply using an address, system calls are used to read or write the position index (which typically post-increments after each data read/write operation, for convenience). | ||
is somewhat more expensive! Rather than simply using an address, | |||
system calls are used to read or write the position index (which | |||
typically post-increments after each data read/write operation, for | |||
convenience). | |||
This treats the file as a (large) array. There is a question as to | This treats the file as a (large) array. There is a question as to what the elements of the array actually are. Sometimes files may have inherent record structures: more usually (these days) they are regarded as bytes and it is up to the application to apply the organisation. | ||
what the elements of the array actually are. Sometimes files may have | |||
inherent record structures: more usually (these days) they are | |||
regarded as bytes and it is up to the application to apply the | |||
organisation. | |||
Unix files are bytes. | Unix files are bytes. | ||
An <em>alternative</em> approach in some operating systems is the ability to | An <em>alternative</em> approach in some operating systems is the ability to [[Memory Mapped Files|map a file]] (or part of a file) into (virtual) address space. It can then be treated as (for example) an array. This can be convenient if a lot of ‘random’ access is required. | ||
[[Memory Mapped Files | map a file]] (or part of a file) into (virtual) address space. | |||
It can then be treated as (for example) an array. This can be | |||
convenient if a lot of ‘random’ access is required. | |||
=== EOF === | === EOF === | ||
Unlike an array in memory – which (at least in principle!) has a | Unlike an array in memory – which (at least in principle!) has a predetermined size – a file can be of (effectively) any length. When treated as a [[Streams | stream]] it is rather useful to know if/when the end has been reached. This can be indicated with an <strong>E</strong>nd <strong>O</strong>f <strong>F</strong>ile marker. | ||
predetermined size – a file can be of (effectively) any length. When | |||
treated as a [[Streams | stream]] it is rather useful to know if/when the | |||
end has been reached. This can be indicated with an <strong>E</strong>nd <strong>O</strong>f | |||
<strong>F</strong>ile marker. | |||
One approach is to reserve a particular control character for this | One approach is to reserve a particular control character for this (<code>^Z</code> a.k.a. <code>SUB</code> has been used in MS-DOS, Windows and other systems). This is fine for printable text; the problem is, of course, there needs to be a way of sending <em>any</em> value in a binary file. | ||
(<code>^Z</code> a.k.a. <code>SUB</code> has been used in MS-DOS, Windows and other | |||
systems). This is fine for printable text; the problem is, of course, | |||
there needs to be a way of sending <em>any</em> value in a binary file. | |||
<strong>Unix</strong> systems have an EOF status which can be read by a <code>feof()</code> | <strong>Unix</strong> systems have an EOF status which can be read by a <code>feof()</code> call from C, for example; if characters are read beyond the end of a file then the value <code>EOF</code> is returned; this is an ‘out of band’ character (usually -1) whereas characters are actually returned as integers, so 257 different return values are possible. | ||
call from C, for example; if characters are read beyond the end of a | |||
file then the value <code>EOF</code> is returned; this is an ‘out of | |||
band’ character (usually -1) whereas characters are actually | |||
returned as integers, so 257 different return values are possible. | |||
EOF status could also be tracked from the file size, of course. | EOF status could also be tracked from the file size, of course. | ||
| Line 122: | Line 65: | ||
{{#widget:UsingFileDemos}} | {{#widget:UsingFileDemos}} | ||
These show the principles of file buffering for reading and writing | These show the principles of file buffering for reading and writing files. The first thing to do, in each case, is to <code>open</code> the file – and the last thing <em>ought</em> to be to close it. | ||
files. The first thing to do, in each case, is to <code>open</code> the file – | |||
and the last thing <em>ought</em> to be to close it. | |||
{{#widget:ReadFile}} | {{#widget:ReadFile}} | ||
| Line 143: | Line 84: | ||
=== Unix – practical file access === | === Unix – practical file access === | ||
Whilst it usually makes no great difference to the user, there are (at | Whilst it usually makes no great difference to the user, there are (at least!) two ways of gaining access to a Unix file from an application. In C, these ‘families’ of library calls are: | ||
least!) two ways of gaining access to a Unix file from an application. | |||
In C, these ‘families’ of library calls are: | |||
*<strong>stdio</strong>: <code>fopen</code>, <code>fclose</code>, <code>fread</code>, <code>fwrite</code> etc. These calls use a <em>pointer</em> to a (concealed) structure which contains the file descriptor. The appropriate library header includes the variables <code>stdin</code> etc. | *<strong>stdio</strong>: <code>fopen</code>, <code>fclose</code>, <code>fread</code>, <code>fwrite</code> etc. These calls use a <em>pointer</em> to a (concealed) structure which contains the file descriptor. The appropriate library header includes the variables <code>stdin</code> etc. | ||
*<strong>sys</strong>: <code>open</code>, <code>close</code>, <code>read</code>, <code>write</code> etc. These calls use the (numeric) file descriptor directly. The appropriate library header includes the definitions <code>STDIN_FILENO</code> etc. | *<strong>sys</strong>: <code>open</code>, <code>close</code>, <code>read</code>, <code>write</code> etc. These calls use the (numeric) file descriptor directly. The appropriate library header includes the definitions <code>STDIN_FILENO</code> etc. | ||
The former set of calls provides an extra layer of indirection and a | The former set of calls provides an extra layer of indirection and a little more formatting – for example <code>fread</code> will read ‘N’ elements of a specified size (e.g. <code>sizeof(int)</code>) whereas <code>read</code> will only read ‘M’ bytes – but otherwise there seems to be no great difference. | ||
little more formatting – for example <code>fread</code> will read | |||
‘N’ elements of a specified size (e.g. <code>sizeof(int)</code>) | |||
whereas <code>read</code> will only read ‘M’ bytes – but otherwise | |||
there seems to be no great difference. | |||
The file descriptor figure is repeated below: the two applications | The file descriptor figure is repeated below: the two applications shown (left) are using different approaches. | ||
shown (left) are using different approaches. | |||
[[Image:file_access.png|link=|alt=File Access Abstraction]] | [[Image:file_access.png|link=|alt=File Access Abstraction]] | ||
---- | ---- | ||
{{BookChapter|13.1.2|532-536}} | |||
{{PageGraph}} | {{PageGraph}} | ||
{{Category|Filing System}} | {{Category|Filing System}} | ||
Latest revision as of 10:03, 5 August 2019
| On path: Filing | 1: Filing System • 2: File Systems • 3: Files • 4: File Attributes • 5: File Types • 6: File Permissions • 7: File Access • 9: Filing System Implementation • 10: I-nodes • 11: Links • 12: File Descriptor |
|---|
| Depends on | Files |
|---|
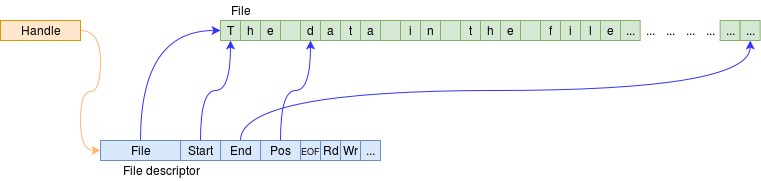
Users usually identify files with filenames … or, more formally, a path to a file. The name is a string which is an inconvenient item for the O.S. to handle. It is therefore usual to associate an abstract handle leading to a file descriptor of a file which is in use.
Exactly what the handle is does not usually matter to a user: it could be a simple index, a virtual address etc. It is just ‘something’ with which the user can identify a particular file.
This gives access to the file descriptor via various ‘method’ calls.
There are accompanying exercises …
The first thing to do is always to open a file – here opened for reading. This will then fetch a block of the file into a buffer which prevents a disk access on every Read call. (Caching again!) Reads are then made from the buffer, which is refilled when necessary.
Read operations can continue until the End Of File, a point which prevents further reading. The file can be closed at any time.
Other things may be mapped to ‘look like’ files and the same, device independent interface. These include:
among other things.
True files – although not purely serial streams – will also allow seek operations where the position read from or written to is moved. A simple example would be a multi-pass compiler which could open a source file and read it serially, then move back to the start and read it again without closing it in the meantime.
The description below covers the ‘classic’ access operations. Some operating systems also allow Memory Mapped Files.
Open
To obtain a file handle it is necessary to “open” a file. This system call will assign a handle to the required filename/path for the relevant process (the last time this string is needed), check and set up the appropriate permissions and reset the file’s (internal position) pointer to the start (or end, if “appending”). It can fail and thus signal various errors.
Close
When a file is finished with it should be “closed”. This may – for example – be needed before another process can write to that file.
Closing the file will also flush any remaining buffered data to the file itself.
The O.S. may close any remaining open files a process owns when the process terminates, but it is good practice to tidy up as a matter of course.
Reading and Writing
For efficiently reducing the number of system calls needed it is usual to read or write blocks of data, although library calls such as fgetc() may reduce this to ‘blocks’ of one byte at a time.
Typical read or write operations move a contiguous number of bytes or words from the current position in a file to a specified memory buffer, or vice versa. The position in the file is advanced by the same distance because file operations are, mostly assumed to be serial.
Seeking
It is possible to apply some ‘random access’ to files in the same way as the computer can to its memory, although the process is somewhat more expensive! Rather than simply using an address, system calls are used to read or write the position index (which typically post-increments after each data read/write operation, for convenience).
This treats the file as a (large) array. There is a question as to what the elements of the array actually are. Sometimes files may have inherent record structures: more usually (these days) they are regarded as bytes and it is up to the application to apply the organisation.
Unix files are bytes.
An alternative approach in some operating systems is the ability to map a file (or part of a file) into (virtual) address space. It can then be treated as (for example) an array. This can be convenient if a lot of ‘random’ access is required.
EOF
Unlike an array in memory – which (at least in principle!) has a predetermined size – a file can be of (effectively) any length. When treated as a stream it is rather useful to know if/when the end has been reached. This can be indicated with an End Of File marker.
One approach is to reserve a particular control character for this (^Z a.k.a. SUB has been used in MS-DOS, Windows and other systems). This is fine for printable text; the problem is, of course, there needs to be a way of sending any value in a binary file.
Unix systems have an EOF status which can be read by a feof() call from C, for example; if characters are read beyond the end of a file then the value EOF is returned; this is an ‘out of band’ character (usually -1) whereas characters are actually returned as integers, so 257 different return values are possible.
EOF status could also be tracked from the file size, of course.
Interactive demonstrations
These show the principles of file buffering for reading and writing files. The first thing to do, in each case, is to open the file – and the last thing ought to be to close it.
Type your file here:
- When reading, opening the file can fetch the first buffer-load of data. The read operations then fetch this from the buffer.
- When the buffer becomes empty, more data is fetched – always assuming that the end of the file hasn’t been reached.
- Progress will stop at EOF
- When a file is opened for writing there will not yet be any data to move to the disk.
- Write operations are buffered, usually until the buffer is full; at this point the buffer is copied to the disk and (notionally) emptied.
- It is possible to
flushthe buffer deliberately, before it is full. - Closing the file will automatically flush any remaining buffered data.
- Crashing out of the operation (e.g.
resethere) may leave data unwritten in the buffer. This may be apparent if software generating a file experiences a segmentation fault (for example).
Unix – practical file access
Whilst it usually makes no great difference to the user, there are (at least!) two ways of gaining access to a Unix file from an application. In C, these ‘families’ of library calls are:
- stdio:
fopen,fclose,fread,fwriteetc. These calls use a pointer to a (concealed) structure which contains the file descriptor. The appropriate library header includes the variablesstdinetc. - sys:
open,close,read,writeetc. These calls use the (numeric) file descriptor directly. The appropriate library header includes the definitionsSTDIN_FILENOetc.
The former set of calls provides an extra layer of indirection and a little more formatting – for example fread will read ‘N’ elements of a specified size (e.g. sizeof(int)) whereas read will only read ‘M’ bytes – but otherwise there seems to be no great difference.
The file descriptor figure is repeated below: the two applications shown (left) are using different approaches.
| Also refer to: | Operating System Concepts, 10th Edition: Chapter 13.1.2, pages 532-536 |
|---|