Filing System: Difference between revisions
pc>Yuron No edit summary |
m (1 revision imported) |
(No difference)
| |
Revision as of 10:03, 5 August 2019
| On path: Filing | 1: Filing System • 2: File Systems • 3: Files • 4: File Attributes • 5: File Types • 6: File Permissions • 7: File Access • 9: Filing System Implementation • 10: I-nodes • 11: Links • 12: File Descriptor |
|---|
| Depends on | Resources • User |
|---|
You should be (at least) reasonably familiar with filing systems – from a user point of view – by now. Thus, this introduction will be quite cursory!
A typical computer might have a number of ‘levels’ of storage. The machine’s (hardware) view is usually something like:
- Processor registers
- Primary memory – chiefly RAM
This probably has some internal cache hierarchy - Secondary storage – typically disks although there may be a variety of physical devices
- Network – not really part of the computer but a source of data nevertheless
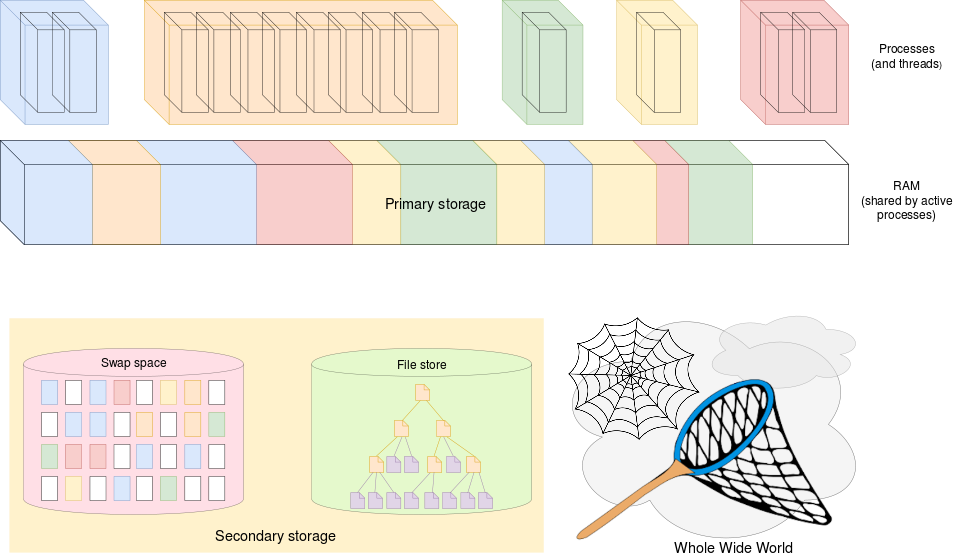
From the user’s perspective the view is simpler.
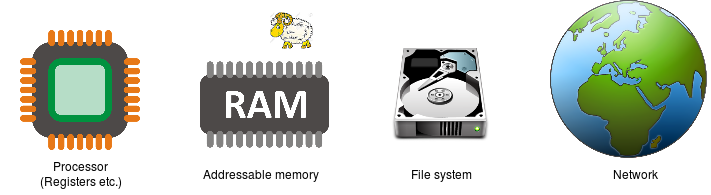
- Internal context (“registers” etc.)
Only relevant for assembler programmers or compiler writers - Memory
- Filestore
- Internet
These are listed from small-&-fast to big-&-slow. There is also the issue of data persistence; due largely to the technology (currently) employed, only file-store and the Internet (someone else’s file-store) retain data indefinitely.
The memory is of (more or less) limited size, set by the machine architecture. For example a 32-bit machine will typically have a limit of 4 GiB … each location with its own address.
File-store is provided to supply the following requirements:
- Large storage capacity
- Data persistence
- Inter-process communication
Large capacity
Rather than storing bytes or words – each with an explicit address – file-store can be larger because it stores ‘items’ as files – of indeterminate size – rather than as (lots of) single bytes. The ‘address’ of an item is a filename rather than a ‘numeric’ address. In practice there is a limit on both the number of different files a particular filing system can handle and the maximum size of any one file but these are both typically large numbers. The total data capacity of the latest systems is still larger than the highest capacity disk drives (although more than one physical drive may be used).
For example: the Linux Ext4 system can support up to a million terabytes, compared with (for example) a large SSD (2018) holding 100 terabytes. In 2019, 14TB hard drives can be obtained on Amazon for reasonable prices, with the best capacity-to-price being offered for 4-8 TB hard drives.
To add some perspective:
- Compact Disc (CD): 700 MB (1982)
- Digital Versatile Disc (DVD): 5 GB - 17 GB (1995)
- Blu-ray: 25/50 GB (2006)
- USB Flash drive: up to 2 TB, though typical sizes are around 128GB to 256GB (as of 2019)
The Internet is even bigger and addresses items via “URL”s, compound addresses specifying a server machine plus a notional file on that server. It’s total capacity is a mystery but must be several exabytes (1018 bytes) (2017) and growing; fortunately it is outside our scope here.
Persistence
Most RAM technologies hold data only whilst continuously powered. This has various consequences in run-time power management but the major issue for most users is that the primary memory data is lost when the power goes off. Secondary storage is persistent. This means it uses different technologies from the ‘main’ memory.
The chief contemporary technologies are:
- Magnetic disk – Hard Disk Drive (HDD)
- Flash memory – Solid State Drive (SSD)
- Optical disc – e.g. DVD
All of these technologies are much slower than the main memory and favour access in blocks rather than true random access.
Flash memory offers some compactness in relatively small storage applications; it is semiconductor store but is significantly slower to read and much much slower to write to than the main RAM. It also has ‘lifetime’ issues, typically only being guaranteed for a limited number of write operations in each ‘block’. This number – somewhere around the 105-106 is satisfactory for many applications – e.g. SD cards – for file-store but not for other secondary applications such as supporting paging.
Access rights
In primary storage there may be threads and processes. Within a process, threads have common access to memory; processes are specifically isolated from each other with protection being enforced in hardware by an MMU.
The philosophy in file-store organisation is typically different; as files are intended to out-live processes it makes no sense for a particular process to ‘own’ a file. Instead, files provide a means of communication both through time and space.
At the same time, some security is important, especially on shared systems. The access control systems for files are typically more sophisticated than for processes as they operate much less frequently than primary memory accesses and can be run in (operating system) software.
Filing system
The filing system lives between the user applications – which want to handle files and the disk (or other) device drivers which move blocks of data to and fro. All processes should see the same files so this common software is clearly part of the operating system. In a ‘layered’ model the filing system is quite a high-level O.S. layer. In a microkernel it may well be run (by the O.S.) in user mode.
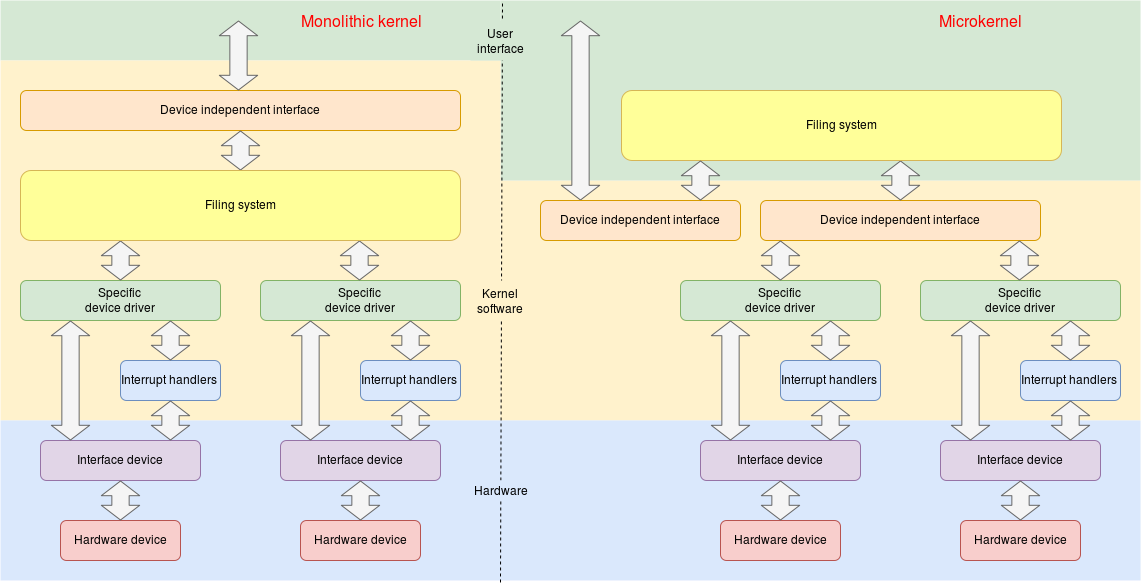
We can – to some extent – decouple the structure of a filing system, as seen by users and outlined here, from the implementation, which is the more ‘technical’ side.
File access
The O.S. provides system calls for access to files: basically operations for reading and writing files … without harmful interactions from different client actions.
File access is developed further in another article.
Overview
The simplest file-stores are ‘flat’: i.e. there is one place where all the files are kept. This soon becomes inconveniently crowded.
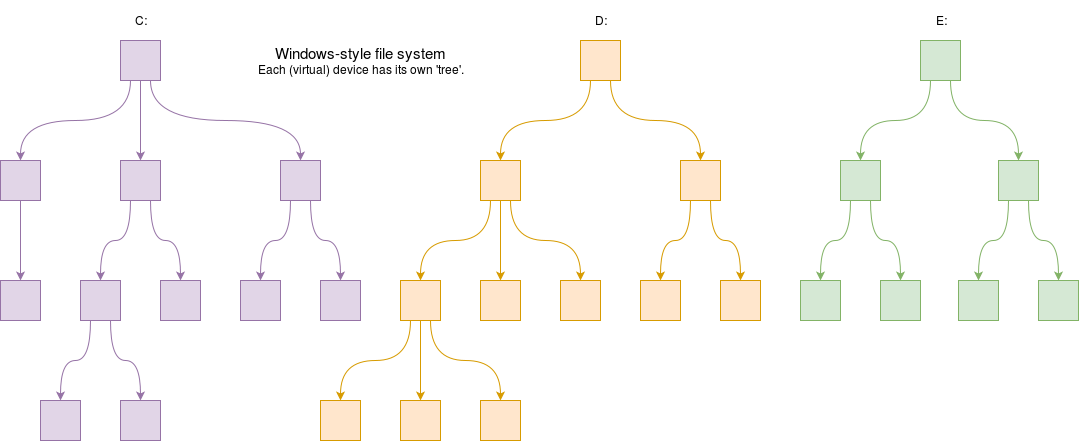
Another mechanism is to identify separate devices, such as “A:” or “C:” evolving through generations and probably ‘familiar’ these days from Windows. In modern systems these may be virtual rather than physically separate devices.
Although these were satisfactory for small file-stores – maybe using interchangeable media – they don’t work well with millions of files.
A modern file-store is most likely to be hierarchical with a tree-like structure of arbitrary depth. Each tree has a single ‘root’ which branches repeatedly. Windows systems still retain separate “roots” for each (virtual) device though.
Unix (on the other hand) file-store mounts devices in a single ‘tree’, so different disks (and other stuff) appear as branches.
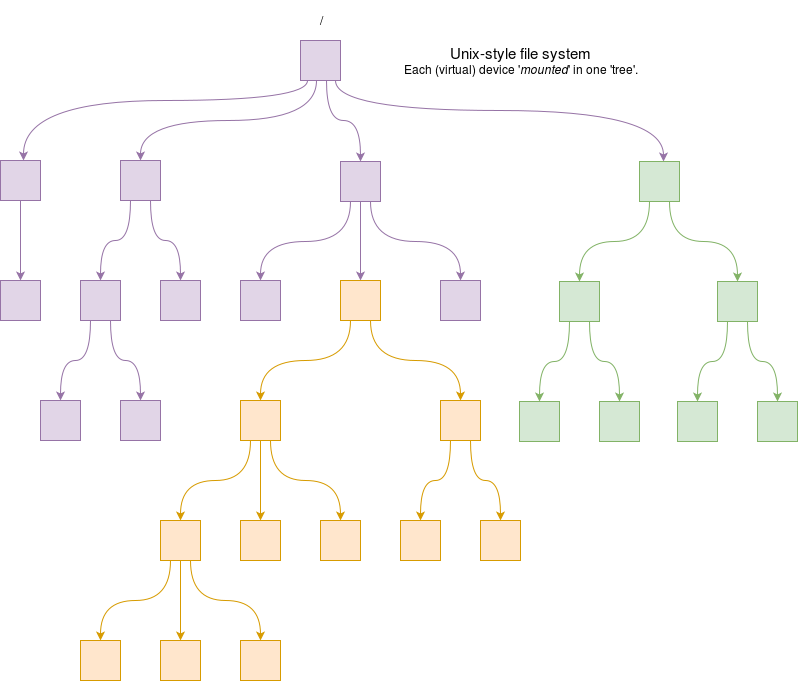
- Branching points are directories – sometimes now called “folders” but we shall stick to “directories” which is more usual in the O.S. context.
A directory can branch zero (empty) or more ways; there is no particular logical limit. - Terminal points on the tree are files, containing data.
“Tree” is an expedient simplification for the moment. When links are considered, the file-store can look like a directed graph.
In a Unix system, when file-store is distributed over an network different machines may see the same files in a different structure. They may also have different properties: for example we mount some systems as read-only on the student network which appear (possibly with a different path/name) as writeable on staff machines: this means every individual file does not need its permission settings checked.
A note on Unix directories
Every Unix directory contains at least two files: these are “.” and “..”. Thus the parent directory
is explicitly specified.
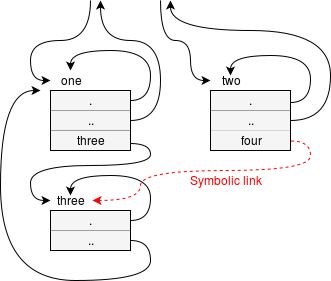
Note four is a symbolic link.
Try setting up a structure as in the figure and cd to directory two. Then try ls four/...
What did you expect?