Inodes: Difference between revisions
m (1 revision imported) |
pc>Yuron No edit summary |
||
| Line 3: | Line 3: | ||
-->{{Path|Filing|10}}<!-- | -->{{Path|Filing|10}}<!-- | ||
-->{{#invoke:Dependencies|add|Filing System Implementation,4}} | -->{{#invoke:Dependencies|add|Filing System Implementation,4}} | ||
Used in Unix systems, an [https://en.wikipedia.org/wiki/Inode i-node] | Used in Unix systems, an [https://en.wikipedia.org/wiki/Inode i-node] is a structure containing some [[File_Attributes|file attributes]] and an array of pointers to blocks used by a particular file. Each i-node has a unique number and is stored in an array, managed by the O.S. An i-node is quite small and need only be kept in <em>memory</em> when the associated file is in use. | ||
is a structure containing some [[File_Attributes|file attributes]] and | |||
an array of pointers to blocks used by a particular file. Each i-node | |||
has a unique number and is stored in an array, managed by the O.S. An | |||
i-node is quite small and need only be kept in <em>memory</em> when the | |||
associated file is in use. | |||
(As mentioned) an i-node is quite small (and a fixed size) thus it can | (As mentioned) an i-node is quite small (and a fixed size) thus it can only point to a limited number of blocks. This could limit the maximum file size rather seriously! | ||
only point to a limited number of blocks. This could limit the | |||
maximum file size rather seriously! | |||
However, not all the blocks need to contain data. A block can, | However, not all the blocks need to contain data. A block can, instead, be filled with pointers to other blocks. This allows | ||
instead, be filled with pointers to other blocks. This allows | considerable expansion. If that is not sufficient the ‘other blocks’ can also be pointers themselves. Some known <em>convention</em> can be used to determine the meaning of each item. | ||
considerable expansion. If that is not sufficient the ‘other | |||
blocks’ can also be pointers themselves. Some known | |||
<em>convention</em> can be used to determine the meaning of each item. | |||
[[Image:inode_array.png|link=|alt=i-node_array]] | [[Image:inode_array.png|link=|alt=i-node_array]] | ||
| Line 26: | Line 16: | ||
[[Image:inodes.png|link=|alt=i-nodes]] | [[Image:inodes.png|link=|alt=i-nodes]] | ||
In this figure a file could be up to 593 blocks long. In a | In this figure a file could be up to 593 blocks long. In a ‘real’ implementation there can be far more pointers in each block, so files could be considerably bigger! | ||
‘real’ implementation there can be far more pointers in | |||
each block, so files could be considerably bigger! | |||
*Small files can be indexed by just the i-node.<br /> (Up to 9 blocks in this example.) | *Small files can be indexed by just the i-node.<br /> (Up to 9 blocks in this example.) | ||
| Line 131: | Line 119: | ||
==== A real example … ==== | ==== A real example … ==== | ||
… may have 15 pointers in the i-node table entry (remember, this is | … may have 15 pointers in the i-node table entry (remember, this is a <em>fixed size</em>). Assume a 512-byte block size and 4-byte pointers, thus 128 pointers can be kept in each additional block: | ||
a <em>fixed size</em>). Assume a 512-byte block size and 4-byte pointers, | |||
thus 128 pointers can be kept in each additional block: | |||
*The first 12 pointers are used directly: file sizes up to 6 KiB. | *The first 12 pointers are used directly: file sizes up to 6 KiB. | ||
| Line 153: | Line 139: | ||
--> | --> | ||
Note: there are <em>some</em> similarities in this approach to the | Note: there are <em>some</em> similarities in this approach to the application of [[Memory_Mapping_Extra|<strong>multi-level page tables</strong>]] … and for much the same reason: it saves precious memory space in the <em>typical</em> cases. | ||
application of [[Memory_Mapping_Extra|<strong>multi-level page tables</strong>]] | |||
… and for much the same reason: it saves precious memory space in | |||
the <em>typical</em> cases. | |||
== Filenames == | == Filenames == | ||
There is no mention of <strong>filenames</strong> in the description above. Files | There is no mention of <strong>filenames</strong> in the description above. Files are identified by a <em>unique, fixed size</em> identifier which is the <strong>i-node number</strong>. These numbers are allocated by the [[Filing_System|filing system]] manager. | ||
are identified by a <em>unique, fixed size</em> identifier which is the | |||
<strong>i-node number</strong>. These numbers are allocated by the [[Filing_System|filing system]] manager. | |||
<blockquote> | <blockquote> | ||
<strong>Experiment:</strong> in a Unix terminal, type <code>ls</code> <code>-i</code> to see a directory <strong>list</strong> including the i-node numbers. | <strong>Experiment:</strong> in a Unix terminal, type <code>ls</code> <code>-i</code> to see a directory <strong>list</strong> including the i-node numbers. | ||
| Line 167: | Line 148: | ||
More detailed explorations are available on line, e.g. [https://www.youtube.com/watch?v=_6VJ8WfWI4k this <strong>video</strong>] (14 mins.) covers this quite thoroughly. | More detailed explorations are available on line, e.g. [https://www.youtube.com/watch?v=_6VJ8WfWI4k this <strong>video</strong>] (14 mins.) covers this quite thoroughly. | ||
</blockquote> | </blockquote> | ||
Filenames are associated with i-node numbers in the directories | Filenames are associated with i-node numbers in the directories (files). This allows an i-node to have <em>multiple names</em>, something which is exploited by [Links links]. | ||
(files). This allows an i-node to have <em>multiple names</em>, something | |||
which is exploited by [Links links]. | |||
---- | ---- | ||
{{BookChapter|14.4.3|575-577}} | |||
{{PageGraph}} | {{PageGraph}} | ||
{{Category|Filing System}} | {{Category|Filing System}} | ||
Revision as of 10:42, 1 August 2019
| On path: Filing | 1: Filing System • 2: File Systems • 3: Files • 4: File Attributes • 5: File Types • 6: File Permissions • 7: File Access • 9: Filing System Implementation • 10: I-nodes • 11: Links • 12: File Descriptor |
|---|
| Depends on | Filing System Implementation |
|---|
Used in Unix systems, an i-node is a structure containing some file attributes and an array of pointers to blocks used by a particular file. Each i-node has a unique number and is stored in an array, managed by the O.S. An i-node is quite small and need only be kept in memory when the associated file is in use.
(As mentioned) an i-node is quite small (and a fixed size) thus it can only point to a limited number of blocks. This could limit the maximum file size rather seriously!
However, not all the blocks need to contain data. A block can, instead, be filled with pointers to other blocks. This allows considerable expansion. If that is not sufficient the ‘other blocks’ can also be pointers themselves. Some known convention can be used to determine the meaning of each item.
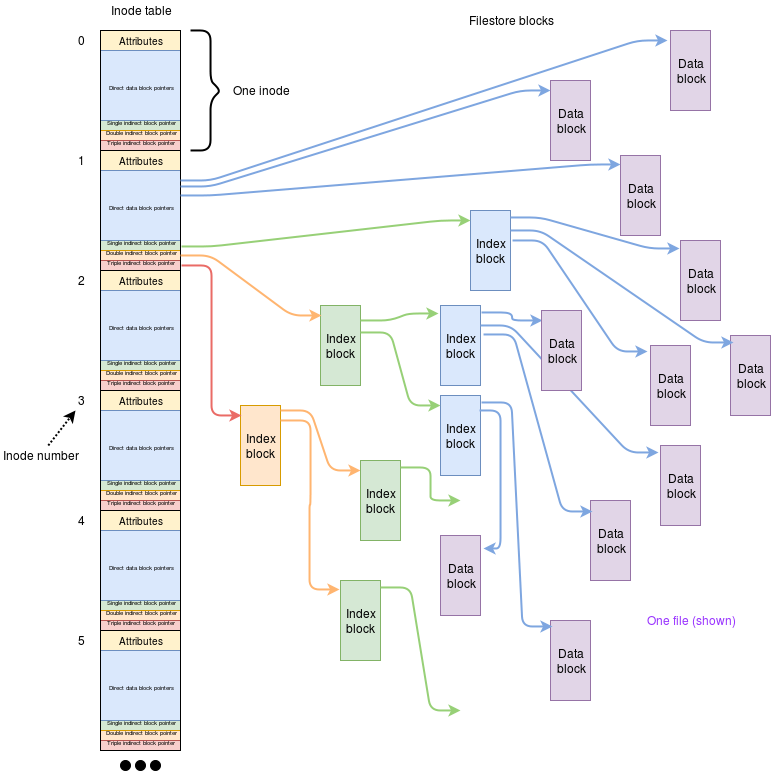
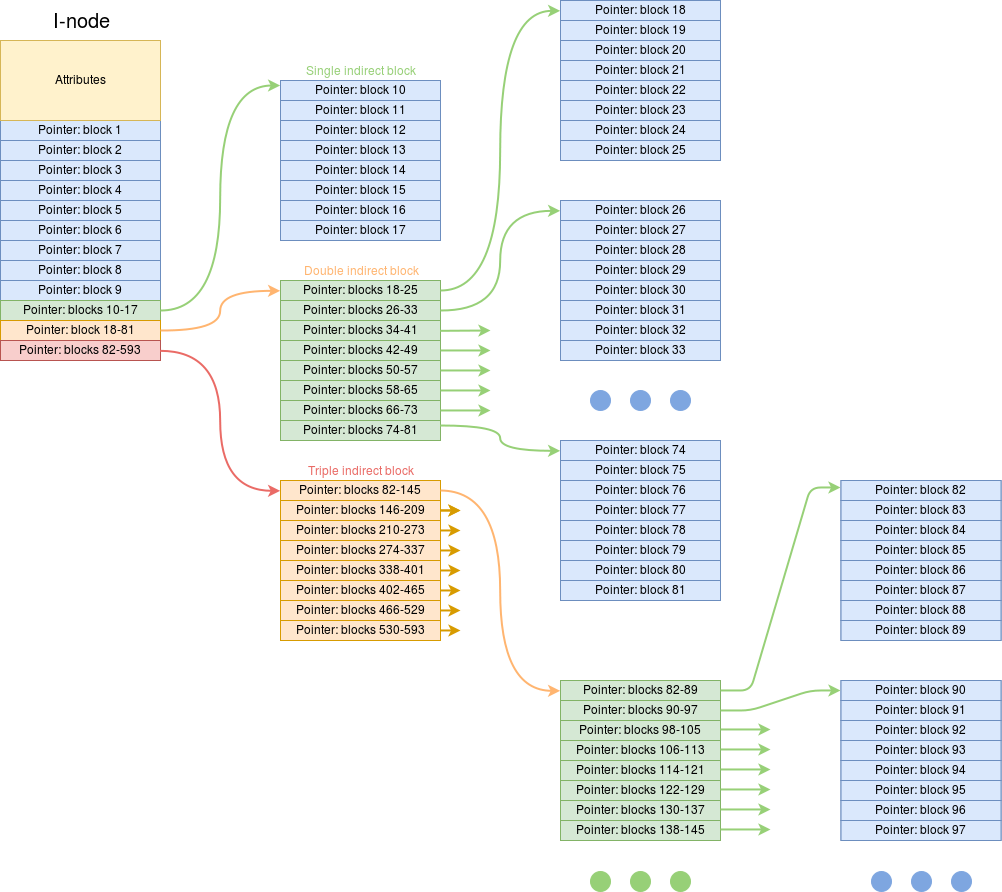
To zoom into a single file specifier in more detail:
In this figure a file could be up to 593 blocks long. In a ‘real’ implementation there can be far more pointers in each block, so files could be considerably bigger!
- Small files can be indexed by just the i-node.
(Up to 9 blocks in this example.) - Larger files can be indexed by the i-node plus an extra block of pointers.
(Up to 17 blocks in this example, but there would really be more pointers in a block than in the original i-node.) - Quite big files use more extra blocks:
(3 extra blocks for up to a 25 block file, 4 for up to 33 etc, up to 10 extra blocks for an 81 block long file.) - Very big files require the above 10 extra blocks plus a few more.
(10 + 3 for up to 89 block files, 14 up to 97 etc.)
In other words, using this (toy) example:
| File blocks | Extra blocks | Total blocks |
|---|---|---|
| 1 | 0 | 1 |
| 2 | 0 | 2 |
| 3 | 0 | 3 |
| 9 | 0 | 9 |
| 10 | 1 | 11 |
| 11 | 1 | 12 |
| 12 | 1 | 13 |
| 17 | 1 | 18 |
| 18 | 3 | 21 |
| 19 | 3 | 22 |
| 25 | 3 | 28 |
| 26 | 4 | 30 |
| 27 | 4 | 31 |
| 33 | 4 | 37 |
| 34 | 5 | 39 |
| 81 | 10 | 91 |
| 82 | 13 | 95 |
| 83 | 13 | 96 |
| 90 | 14 | 104 |
| 98 | 15 | 113 |
| 145 | 20 | 165 |
| 146 | 22 | 168 |
A real example …
… may have 15 pointers in the i-node table entry (remember, this is a fixed size). Assume a 512-byte block size and 4-byte pointers, thus 128 pointers can be kept in each additional block:
- The first 12 pointers are used directly: file sizes up to 6 KiB.
- Pointer 13 is single-indirect, allowing for files up to (12 + 128) blocks – 140 KiB
- Pointer 14 is double-indirect, allowing for files up to (12 + 128+ 1282) blocks – about 8.2 MiB
- Pointer 15 is triple-indirect, allowing for files up to (12 + 128+ 1282+ 1283) blocks – about 1 GiB
Not enough? Use bigger blocks.
Note: there are some similarities in this approach to the application of multi-level page tables … and for much the same reason: it saves precious memory space in the typical cases.
Filenames
There is no mention of filenames in the description above. Files are identified by a unique, fixed size identifier which is the i-node number. These numbers are allocated by the filing system manager.
Experiment: in a Unix terminal, type
ls-ito see a directory list including the i-node numbers. More detailed explorations are available on line, e.g. this video (14 mins.) covers this quite thoroughly.
Filenames are associated with i-node numbers in the directories (files). This allows an i-node to have multiple names, something which is exploited by [Links links].
| Also refer to: | Operating System Concepts, 10th Edition: Chapter 14.4.3, pages 575-577 |
|---|