Interprocess Communication: Difference between revisions
m 1 revision imported |
m 1 revision imported |
||
| (One intermediate revision by one other user not shown) | |||
| Line 1: | Line 1: | ||
{{#set: Priority=4 | Summary=Some high-level notes on how two or more independent processes may communicate.}}<!-- | {{#set: Priority=4 | Summary=Some high-level notes on how two or more independent processes may communicate.}}<!-- | ||
-->{{Path|IPC|2}}{{Path|Processes| | -->{{Path|IPC|2}}{{Path|Processes|6}}<!-- | ||
-->{{#invoke:Dependencies|add|Processes,3|IO,2}} | -->{{#invoke:Dependencies|add|Processes,3|IO,2}} | ||
Sometimes <strong>processes</strong> just ‘do their own thing’, | Sometimes <strong>processes</strong> just ‘do their own thing’, independently. However multiprocessing is a <em>resource</em> which can be exploited by the programmer and then there is often the need to communicate between processes. | ||
independently. However multiprocessing is a <em>resource</em> which can be | |||
exploited by the programmer and then there is often the need to | |||
communicate between processes. | |||
As each <strong>process</strong> has its own [[context]] – deliberately | As each <strong>process</strong> has its own [[context]] – deliberately protected from other processes – interprocess communication requires some form of operating system intervention. Note that this is not always the case when communicating between threads (they may share variables implicitly, for example) but many of the <em>principles</em> are the same in any case. | ||
protected from other processes – interprocess communication requires | |||
some form of operating system intervention. Note that this is not | |||
always the case when communicating between threads (they may share | |||
variables implicitly, for example) but many of the <em>principles</em> are | |||
the same in any case. | |||
There are numerous ways to communicate between processes, different | There are numerous ways to communicate between processes, different approaches being appropriate to different circumstances. Some major categories are listed below. | ||
approaches being appropriate to different circumstances. Some major | |||
categories are listed below. | |||
Each of these has its own advantages and disadvantages; some can be | Each of these has its own advantages and disadvantages; some can be used to implement others. However these categories will illustrate the sort of facilities and their applications which can be used internally and provided for users. | ||
used to implement others. However these categories will illustrate the | |||
sort of facilities and their applications which can be used internally | |||
and provided for users. | |||
---- | ---- | ||
==== [[Shared Memory]] ==== | ==== [[Shared Memory]] ==== | ||
If processes (or threads!) share some RAM they can obviously | If processes (or threads!) share some RAM they can obviously communicate using that. As the processes run <em>asynchronously</em> some form of protocol is usually necessary to ensure data are seen correctly. | ||
communicate using that. As the processes run <em>asynchronously</em> some | |||
form of protocol is usually necessary to ensure data are seen | |||
correctly. | |||
[[Image:comms_shared_mem.png|link=|alt=Communication via shared memory]] | [[Image:comms_shared_mem.png|link=|alt=Communication via shared memory]] | ||
A simple protocol could be to have an array of data and a Boolean | A simple protocol could be to have an array of data and a Boolean flag. When the flag is FALSE, one process (the | ||
flag. When the flag is FALSE, one process (the | “producer”) can write into the array. When it has completed this it can write a TRUE to the flag. It must then wait until the flag is FALSE before writing again. | ||
“producer”) can write into the array. When it has | |||
completed this it can write a TRUE to the flag. It must then wait | |||
until the flag is FALSE before writing again. | |||
Conversely, the other process (the “consumer”) waits for | Conversely, the other process (the “consumer”) waits for the flag to be TRUE before proceeding. It then knows that there is | ||
the flag to be TRUE before proceeding. It then knows that there is | valid data and it can interpret this. When this is complete it can set the flag to FALSE so that more data can be sent. | ||
valid data and it can interpret this. When this is complete it can | |||
set the flag to FALSE so that more data can be sent. | |||
This simple interlock is safe and is <strong>lock free</strong> as the write | This simple interlock is safe and is <strong>lock free</strong> as the write operations are [[Atomicity|atomic]]. More elaborate communications can be contrived but they <em>may</em> need [[Locks|<strong>locks</strong>]] such as [[Semaphores|<strong>semaphores</strong>]] for safe control. | ||
operations are [[Atomicity|atomic]]. More elaborate communications can | |||
be contrived but they <em>may</em> need [[Locks|<strong>locks</strong>]] such as | |||
[[Semaphores|<strong>semaphores</strong>]] for safe control. | |||
With a shared memory the communications <em>protocol</em> largely devolves to | With a shared memory the communications <em>protocol</em> largely devolves to the application. This is workable in many situations and may be ‘cheaper’ than using system calls. However, if making your own communications structures, note a couple of <strong>important</strong> points. | ||
the application. This is workable in many situations and may be | |||
‘cheaper’ than using system calls. However, if making | |||
your own communications structures, note a couple of <strong>important</strong> | |||
points. | |||
*What you see as an [[Atomicity|atomic]] statement in your source code (e.g. <code>i++;</code>) may not be atomic to the processor (<code>load i; i = i + 1; store i;</code>) and the sequence could be interrupted, including containing a [Context_Switching context switch]. | *What you see as an [[Atomicity|atomic]] statement in your source code (e.g. <code>i++;</code>) may not be atomic to the processor (<code>load i; i = i + 1; store i;</code>) and the sequence could be interrupted, including containing a [[Context_Switching|context switch]]. | ||
*Compilers and high-performance processors may <em>reorder</em> operations to increase execution speed. In general this is a Good Thing but this could, <em>invisibly</em>, break a carefully crafted protocol.<br /> (See also: “[[Memory_Barrier|memory barriers]]”.) | *Compilers and high-performance processors may <em>reorder</em> operations to increase execution speed. In general this is a Good Thing but this could, <em>invisibly</em>, break a carefully crafted protocol.<br /> (See also: “[[Memory_Barrier|memory barriers]]”.) | ||
There’s a [https://en.wikipedia.org/wiki/Memory_ordering whole topic] | There’s a [https://en.wikipedia.org/wiki/Memory_ordering whole topic] in itself, here! So, be very cautious of use the facilities already provided by the O.S. or language libraries, such as [[Pipes]]. | ||
in itself, here! So, be very cautious of use the facilities already | |||
provided by the O.S. or language libraries, such as [[Pipes]]. | |||
==== [[Files]] ==== | ==== [[Files]] ==== | ||
Processes may communicate by altering file-system contents, which are | Processes may communicate by altering file-system contents, which are visible to all processes on the system which have the permission to read them. Using the file system is convenient for large quantities of data but the overheads are significant for ‘day-to-day’ operations. | ||
visible to all processes on the system which have the permission to | |||
read them. Using the file system is convenient for large quantities | |||
of data but the overheads are significant for ‘day-to-day’ | |||
operations. | |||
==== Messages ==== | ==== Messages ==== | ||
Messages are data ‘blocks’ sent from process to process – | Messages are data ‘blocks’ sent from process to process – perhaps from machine to machine. In fetching a web page your browser | ||
perhaps from machine to machine. In fetching a web page your browser | is exchanging messages with a (probably remote) server. They are (clearly?) a means of communicating where there is no memory or file-store in common although messages can be passed on the same machine too. | ||
is exchanging messages with a (probably remote) server. They are | |||
(clearly?) a means of communicating where there is no memory or | |||
file-store in common although messages can be passed on the same | |||
machine too. | |||
When passing a message, the producer and consumer must coordinate on a | When passing a message, the producer and consumer must coordinate on a one-to-one basis: one message sent, one message received. They will typically be in order <strong>but</strong> beware if passing across a network which can route packets dynamically (e.g. the Internet). | ||
one-to-one basis: one message sent, one message received. They will | |||
typically be in order <strong>but</strong> beware if passing across a network which | |||
can route packets dynamically (e.g. the Internet). | |||
It can be important to know whether message passing is synchronised or | It can be important to know whether message passing is synchronised or not. In a ''synchronous message passing'' system to | ||
not. In a ''synchronous message passing'' system to | ‘output’ and the ‘input’ operations are compelled to meet. Whichever arrives at the <strong>rendezvous</strong> first is | ||
‘output’ and the ‘input’ operations are | blocked until the other arrives. This is typically less efficient in processor time but can give more information/control over process sequencing. | ||
compelled to meet. Whichever arrives at the <strong>rendezvous</strong> first is | |||
blocked until the other arrives. This is typically less efficient in | |||
processor time but can give more information/control over process | |||
sequencing. | |||
[[Image:message_sync.png|link=|alt=Synchronous message passing]] | [[Image:message_sync.png|link=|alt=Synchronous message passing]] | ||
=== <!-- spacer --> === | === <!-- spacer --> === | ||
With <strong>asynchronous message passing</strong> there is the concept of | With <strong>asynchronous message passing</strong> there is the concept of <em>elasticity</em>, where a message queue is maintained so the producer may get some ‘distance’ ahead of the consumer. This gives greater freedom of operation but less control over timing. The communication is much like a <strong>pipe</strong> although the messages will usually have some recognised structure. | ||
<em>elasticity</em>, where a message queue is maintained so the producer may | |||
get some ‘distance’ ahead of the consumer. This gives | |||
greater freedom of operation but less control over timing. The | |||
communication is much like a <strong>pipe</strong> although the messages will | |||
usually have some recognised structure. | |||
[[Image:message_async.png|link=|alt=Asynchronous message passing]] | [[Image:message_async.png|link=|alt=Asynchronous message passing]] | ||
| Line 108: | Line 58: | ||
==== Pipes ==== | ==== Pipes ==== | ||
A Unix ‘[[Pipes|pipe]]’ – a concept adopted by other | A Unix ‘[[Pipes|pipe]]’ – a concept adopted by other operating systems – is a [[Queues|FIFO]] which can be used to connect | ||
operating systems – is a [[Queues|FIFO]] which can be used to connect | processes. One process is able to write (e.g. bytes) into the FIFO; a (presumably) different process can read them. Ordering is preserved but there is no data structure per se. | ||
processes. One process is able to write (e.g. bytes) into the FIFO; a | |||
(presumably) different process can read them. Ordering is preserved | |||
but there is no data structure per se. | |||
There’s an opportunity to create pipes in [[Exercises:Pipes|this exercise]]; you can also do this from a [[shell]] by creating a <em>named pipe</em> by following the instructions in [[Pipes|this article]]. | There’s an opportunity to create pipes in [[Exercises:Pipes|this exercise]]; you can also do this from a [[shell]] by creating a <em>named pipe</em> by following the instructions in [[Pipes|this article]]. | ||
| Line 119: | Line 66: | ||
==== Barriers ==== | ==== Barriers ==== | ||
A synchronisation barrier is a means of ensuring no process or thread | A synchronisation barrier is a means of ensuring no process or thread can cause problems by getting too far ahead of others it is working with. (This is not passing <em>data</em> per se, but is still communicating information between processes.) A simple example will suffice. | ||
can cause problems by getting too far ahead of others it is working | |||
with. (This is not passing <em>data</em> per se, but is still communicating | |||
information between processes.) A simple example will suffice. | |||
Imagine running (say) four processes which all do some tasks with | Imagine running (say) four processes which all do some tasks with unpredictable timing. Before proceeding further it is important that <em>all</em> the tasks are complete. A barrier will provide this assurance. | ||
unpredictable timing. Before proceeding further it is important that | |||
<em>all</em> the tasks are complete. A barrier will provide this assurance. | |||
[[Image:sync_barrier.png|link=|alt=Synchronisation barrier]] | [[Image:sync_barrier.png|link=|alt=Synchronisation barrier]] | ||
An [[ | An [[Barrier demo|animated demonstration]] with a possible implementation mechanism is available. | ||
implementation mechanism is available. | |||
Synchronisation in this way is useful in any parallel application, not | Synchronisation in this way is useful in any parallel application, not just operating systems’ code. For <strong>example</strong>, consider a problem such as [https://en.wikipedia.org/wiki/Numerical_weather_prediction weather forecasting] – typically done with massively parallel supercomputers. The world is divided into ‘cells’; in each cell differential equations are solved dealing with the variation in temperature, air pressure etc. for a time step (between a minute and an hour of simulated time) after which information about the boundaries of each cell needs to be communicated to its neighbours. The internal time step calculations are distributed across many processors (each simulating many adjacent cells) and these can run in parallel <em>but</em> it is important that cell boundaries synchronise to swap results at the same simulated time. | ||
just operating systems’ code. For <strong>example</strong>, consider a problem | |||
such as [https://en.wikipedia.org/wiki/Numerical_weather_prediction weather forecasting] | |||
– typically done with massively parallel supercomputers. The world | |||
is divided into ‘cells’; in each cell differential | |||
equations are solved dealing with the variation in temperature, air | |||
pressure etc. for a time step (between a minute and an hour of | |||
simulated time) after which information about the boundaries of each | |||
cell needs to be communicated to its neighbours. The internal time | |||
step calculations are distributed across many processors (each | |||
simulating many adjacent cells) and these can run in parallel <em>but</em> it | |||
is important that cell boundaries synchronise to swap results at the | |||
same simulated time. | |||
<blockquote> | <blockquote> | ||
Another (relevant) use of the term “barrier” is the | Another (relevant) use of the term “barrier” is the [[Memory_Barrier|memory barrier]], which works on the same principle (complete all operations in one set before doing any in the next set) at the level of machine operations (loads and stores) rather than processes. | ||
[[Memory_Barrier|memory barrier]], which works on the same principle | |||
(complete all operations in one set before doing any in the next | |||
set) at the level of machine operations (loads and stores) rather | |||
than processes. | |||
</blockquote> | </blockquote> | ||
---- | ---- | ||
{{BookChapter|3.4-3.7|123-145}} | |||
{{PageGraph}} | {{PageGraph}} | ||
{{Category|IO}} | {{Category|IO}} | ||
{{Category|Processes}} | {{Category|Processes}} | ||
Latest revision as of 10:03, 5 August 2019
| On path: IPC | 1: Processes • 2: Interprocess Communication • 3: Shared Memory • 4: Files • 5: Unix Signals • 6: Pipes • 7: Sockets • 8: Synchronisation • 9: Synchronisation Barrier • 10: Atomicity • 11: Mutual exclusion • 12: Signal and Wait |
|---|
| On path: Processes | 1: Processes • 2: Context • 3: Process Control Block (PCB) • 4: Multi Threading • 5: Threads • 6: Interprocess Communication • 7: Process Scheduling • 8: Scheduler • 9: Process States • 10: Process Priority |
|---|
| Depends on | Processes • IO |
|---|
Sometimes processes just ‘do their own thing’, independently. However multiprocessing is a resource which can be exploited by the programmer and then there is often the need to communicate between processes.
As each process has its own context – deliberately protected from other processes – interprocess communication requires some form of operating system intervention. Note that this is not always the case when communicating between threads (they may share variables implicitly, for example) but many of the principles are the same in any case.
There are numerous ways to communicate between processes, different approaches being appropriate to different circumstances. Some major categories are listed below.
Each of these has its own advantages and disadvantages; some can be used to implement others. However these categories will illustrate the sort of facilities and their applications which can be used internally and provided for users.
If processes (or threads!) share some RAM they can obviously communicate using that. As the processes run asynchronously some form of protocol is usually necessary to ensure data are seen correctly.
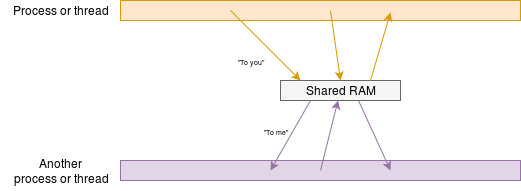
A simple protocol could be to have an array of data and a Boolean flag. When the flag is FALSE, one process (the “producer”) can write into the array. When it has completed this it can write a TRUE to the flag. It must then wait until the flag is FALSE before writing again.
Conversely, the other process (the “consumer”) waits for the flag to be TRUE before proceeding. It then knows that there is valid data and it can interpret this. When this is complete it can set the flag to FALSE so that more data can be sent.
This simple interlock is safe and is lock free as the write operations are atomic. More elaborate communications can be contrived but they may need locks such as semaphores for safe control.
With a shared memory the communications protocol largely devolves to the application. This is workable in many situations and may be ‘cheaper’ than using system calls. However, if making your own communications structures, note a couple of important points.
- What you see as an atomic statement in your source code (e.g.
i++;) may not be atomic to the processor (load i; i = i + 1; store i;) and the sequence could be interrupted, including containing a context switch. - Compilers and high-performance processors may reorder operations to increase execution speed. In general this is a Good Thing but this could, invisibly, break a carefully crafted protocol.
(See also: “memory barriers”.)
There’s a whole topic in itself, here! So, be very cautious of use the facilities already provided by the O.S. or language libraries, such as Pipes.
Files
Processes may communicate by altering file-system contents, which are visible to all processes on the system which have the permission to read them. Using the file system is convenient for large quantities of data but the overheads are significant for ‘day-to-day’ operations.
Messages
Messages are data ‘blocks’ sent from process to process – perhaps from machine to machine. In fetching a web page your browser is exchanging messages with a (probably remote) server. They are (clearly?) a means of communicating where there is no memory or file-store in common although messages can be passed on the same machine too.
When passing a message, the producer and consumer must coordinate on a one-to-one basis: one message sent, one message received. They will typically be in order but beware if passing across a network which can route packets dynamically (e.g. the Internet).
It can be important to know whether message passing is synchronised or not. In a synchronous message passing system to ‘output’ and the ‘input’ operations are compelled to meet. Whichever arrives at the rendezvous first is blocked until the other arrives. This is typically less efficient in processor time but can give more information/control over process sequencing.
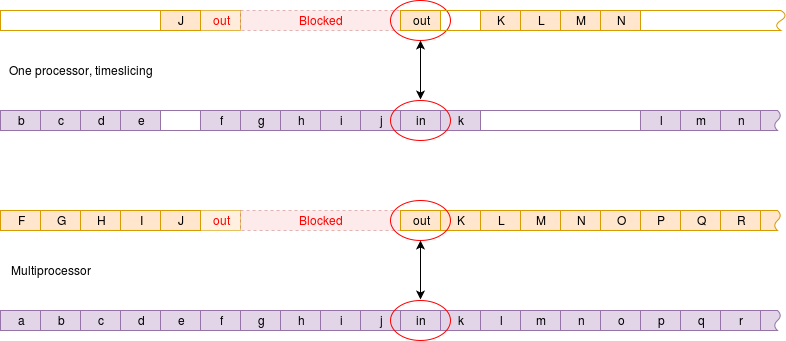
With asynchronous message passing there is the concept of elasticity, where a message queue is maintained so the producer may get some ‘distance’ ahead of the consumer. This gives greater freedom of operation but less control over timing. The communication is much like a pipe although the messages will usually have some recognised structure.

Signals
The term “signal” is used in different ways.
- Wait & signal: a means of synchronisation where processes (or threads) block and unblock others.
- In Unix (at least) “Signal” is used as a term for asynchronous events. These events are similar in principle to interrupts although they are software generated, mediated by the O.S.
In terms of interprocess communication, signal calls can request a process to stop or start, indicate anomalies etc. A ‘familiar’ signal example is probably pressing^Cin a shell to interrupt a running process.
There’s a chance to program around some signals in this exercise.
Pipes
A Unix ‘pipe’ – a concept adopted by other operating systems – is a FIFO which can be used to connect processes. One process is able to write (e.g. bytes) into the FIFO; a (presumably) different process can read them. Ordering is preserved but there is no data structure per se.
There’s an opportunity to create pipes in this exercise; you can also do this from a shell by creating a named pipe by following the instructions in this article.
Pipes may carry data streams or more structured messages.
Barriers
A synchronisation barrier is a means of ensuring no process or thread can cause problems by getting too far ahead of others it is working with. (This is not passing data per se, but is still communicating information between processes.) A simple example will suffice.
Imagine running (say) four processes which all do some tasks with unpredictable timing. Before proceeding further it is important that all the tasks are complete. A barrier will provide this assurance.
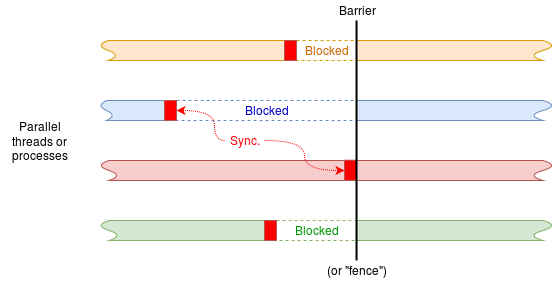
An animated demonstration with a possible implementation mechanism is available.
Synchronisation in this way is useful in any parallel application, not just operating systems’ code. For example, consider a problem such as weather forecasting – typically done with massively parallel supercomputers. The world is divided into ‘cells’; in each cell differential equations are solved dealing with the variation in temperature, air pressure etc. for a time step (between a minute and an hour of simulated time) after which information about the boundaries of each cell needs to be communicated to its neighbours. The internal time step calculations are distributed across many processors (each simulating many adjacent cells) and these can run in parallel but it is important that cell boundaries synchronise to swap results at the same simulated time.
Another (relevant) use of the term “barrier” is the memory barrier, which works on the same principle (complete all operations in one set before doing any in the next set) at the level of machine operations (loads and stores) rather than processes.
| Also refer to: | Operating System Concepts, 10th Edition: Chapter 3.4-3.7, pages 123-145 |
|---|