Structures: Difference between revisions
m 1 revision imported |
pc>Yuron No edit summary |
||
| Line 4: | Line 4: | ||
Traditionally called a [https://en.wikipedia.org/wiki/Record_(computer_science) <strong>record</strong>] these are probably known mostly to programmers by the C term <strong><code>struct</code></strong>. They are basically like the <em>data</em> parts of an <em>object</em> in Java et alia. | Traditionally called a [https://en.wikipedia.org/wiki/Record_(computer_science) <strong>record</strong>] these are probably known mostly to programmers by the C term <strong><code>struct</code></strong>. They are basically like the <em>data</em> parts of an <em>object</em> in Java et alia. | ||
The examples below use C syntax, which is a bit obscure: hopefully the | The examples below use C syntax, which is a bit obscure: hopefully the figure will help to clarify what the syntax means! | ||
figure will help to clarify what the syntax means! | |||
[[Image:struct.png|link=|alt=Structure figure]] | [[Image:struct.png|link=|alt=Structure figure]] | ||
| Line 24: | Line 23: | ||
** <code>.</code> is used because <code>instantiated</code> <em>is</em> the record in question. | ** <code>.</code> is used because <code>instantiated</code> <em>is</em> the record in question. | ||
If that’s confusing – it probably is, first time (and second time) | If that’s confusing – it probably is, first time (and second time) through – just go through it slowly. The syntax is not nice, but it does make logical sense. (Eventually.) | ||
through – just go through it slowly. The syntax is not nice, but it | |||
does make logical sense. | |||
(Eventually.) | |||
---- | ---- | ||
| Line 51: | Line 47: | ||
The NULL would be overwritten to point back at the original (upper) structure. | The NULL would be overwritten to point back at the original (upper) structure. | ||
<blockquote>This would be a slightly odd thing to do, as it links the two records in a circular chain although it has not caused a memory leak as we can still find the dynamically allocated structure. | <blockquote>This would be a slightly odd thing to do, as it links the two records in a circular chain although it has not caused a memory leak as we can still find the dynamically allocated structure. (If we look hard enough!) | ||
(If we look hard enough!) | |||
</blockquote> | </blockquote> | ||
</div></div> | </div></div> | ||
| Line 116: | Line 111: | ||
==== Even a bit more detail! ==== | ==== Even a bit more detail! ==== | ||
On the other hand, a <em>naive</em> compiler might leave spaces in the record | On the other hand, a <em>naive</em> compiler might leave spaces in the record to <em>align</em> the longer fields. A ‘cleverer’ compiler might pick a <em>reorder</em> from the source code for compactness. See the figure below, showing memory 64-bits wide, for details. | ||
to <em>align</em> the longer fields. A ‘cleverer’ compiler might | |||
pick a <em>reorder</em> from the source code for compactness. See the figure | |||
below, showing memory 64-bits wide, for details. | |||
<syntaxhighlight lang="C"> | <syntaxhighlight lang="C"> | ||
typedef struct example_type_2 | typedef struct example_type_2 | ||
| Line 155: | Line 147: | ||
[[Image:struct_examples.png|link=|alt=Structure examples]] | [[Image:struct_examples.png|link=|alt=Structure examples]] | ||
<strong>Alignment</strong> onto <strong>word</strong> boundaries – we have a 64-bit machine here | <strong>Alignment</strong> onto <strong>word</strong> boundaries – we have a 64-bit machine here – will make memory access more efficient (but this is moving into hardware architecture). | ||
– will make memory access more efficient (but this is moving into | |||
hardware architecture). | |||
---- | ---- | ||
Revision as of 13:51, 4 August 2019
| On path: Pointers | 1: Memory • 2: Arrays • 3: Pointers • 4: Pointer Exercise • 5: Structures • 6: Dynamic Memory Allocation • 7: Malloc Exercise • 8: Structs Exercise |
|---|
| Depends on | Memory |
|---|
Traditionally called a record these are probably known mostly to programmers by the C term struct. They are basically like the data parts of an object in Java et alia.
The examples below use C syntax, which is a bit obscure: hopefully the figure will help to clarify what the syntax means!
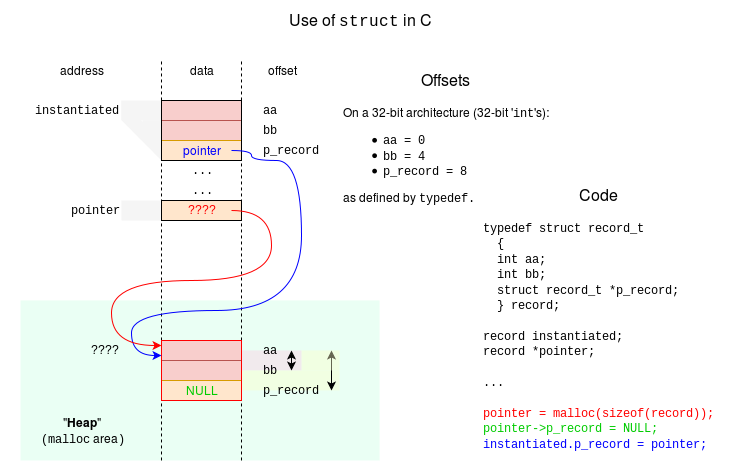
In the code, declarations are in black:
typedefdefines a structure (like a ‘class’) which has some offsets.- Two variables are declared:
instantiated, which is arecordpointerwhich is a pointer.
The dynamically executed statements are in colours:
- a new record is created and its address stored in
pointer; this address of this record was not known to the compiler. - the field p_record of the new record is set to
NULL.->is used becausepointeris not the record, it is a pointer to it.
- the field p_record of the
instantiatedrecord copied frompointer..is used becauseinstantiatedis the record in question.
If that’s confusing – it probably is, first time (and second time) through – just go through it slowly. The syntax is not nice, but it does make logical sense. (Eventually.)
Test
If you’re feeling brave, try these:
- What value is at
instantiated.p_record->p_record?
The value is NULL.
instantiated.p_record is a pointer; its value points to the (lower) structure.
->p_record addresses the p_record field at that pointer.
The contents of that field is a NULL.
- What would happen if the next statement was the one below?
pointer->p_record = &instantiated;
The NULL would be overwritten to point back at the original (upper) structure.
This would be a slightly odd thing to do, as it links the two records in a circular chain although it has not caused a memory leak as we can still find the dynamically allocated structure. (If we look hard enough!)
- How could you assign
pointerto point to the statically instantiated record?
pointer = &instantiated;
pointer (contents) becomes the address instantiated.
Still baffled?
Try this analogy: a structure is like an array but:
- the elements can be different sizes
- the indices have fixed names rather than being numbers
- the syntax looks different
Thus, for a system which (for example) has 32-bit integers and 64-bit pointers:
typedef struct example_type_1
{
int first; // 4 bytes
int second; // 4 bytes
int *third; // 8 bytes (pointer)
int fourth; // 4 bytes
} example;
would (probably) set the following (byte, decimal) offsets:
| field | offset |
|---|---|
| first | 0 |
| second | 4 |
| third | 8 |
| fourth | 16 |
Although this is really up to the compiler and it could choose differently. There is no real need for you to know.
Thus:
example_1.fourth = 1234;
is sort of like:
example_1[16] = 1234;
(except the ‘array index’ has been scaled already to the byte address).
Even a bit more detail!
On the other hand, a naive compiler might leave spaces in the record to align the longer fields. A ‘cleverer’ compiler might pick a reorder from the source code for compactness. See the figure below, showing memory 64-bits wide, for details.
typedef struct example_type_2
{
int alpha; // 4 bytes
int *beta; // 8 bytes (pointer)
int gamma; // 4 bytes
int *delta; // 8 bytes (pointer)
} example;
would (probably) set the following (byte, decimal) offsets:
| field | (naive) offset | (clever) offset |
|---|---|---|
| alpha | 0 | 0 |
| beta | 8 | 8 |
| gamma | 16 | 4 |
| delta | 24 | 16 |

Alignment onto word boundaries – we have a 64-bit machine here – will make memory access more efficient (but this is moving into hardware architecture).